多智能体强化学习算法及环境
Pytorch实现的多智能体强化学习算法,包括IQL、QMIX、VDN、COMA、QTRAN(QTRAN-base和QTRAN-alt)、MAVEN、CommNet、DyMA-CL和G2ANet,这些都是最先进的MARL算法。SMAC是星际争霸II的分散式微观管理场景。
项目地址:
https://github.com/starry-sky6688/StarCraft
运行:
python main.py --map=3m --alg=qmix
直接运行 ,然后算法将在map上开始训练。
MRL环境配置
星际争霸II 环境: https://github.com/oxwhirl/smac
安装星际争霸 II
SMAC基于星际争霸II的完整游戏(版本>= 3.16.1)。要安装游戏,请按照下面的命令操作。
- Linux
请使用暴雪的存储库下载 Linux 版本的《星际争霸 II》。默认情况下,游戏应位于目录中。这可以通过设置环境变量来更改。~/StarCraftII/SC2PATH
- MacOS/Windows
请从Battle.net安装星际争霸 II。免费的入门版也有效。如果您使用默认安装位置,PySC2 将找到最新的二进制文件。否则,与Linux版本类似,您需要使用游戏的正确位置设置环境变量。SC2PATH
SMAC 地图
SMAC由许多具有预配置地图的战斗场景组成。在SMAC可以使用之前,这些地图需要下载到星际争霸II的目录中。Maps
下载SMAC地图并将其解压缩到您的目录中。如果您通过 git 安装了 SMAC,只需将目录从复制到目录中即可。
在根目录下新建一个文件夹Maps
将文件保存到星际争霸Maps文件夹内。
运行
python main.py --map=3m --alg=qmix
环境配置,感觉有点问题,其实修改有个python文件夹里面的地址即可,不需要配置什么环境变量。
报错的文件,点进去找到C:修改为F:即可。
结果
MADDPG
git上找到的都运行不了,测试了很久,在https://github.com/starry-sky6688/MADDPG 的基础上改了一下,成功运行。
多智能体环境
- 安装方法1:
cd into the root directory and type pip install -e .
pip install pettingzoo[mpe]
Requirements
python=3.6.5
Multi-Agent Particle Environment(MPE)
torch=1.1.0
运行
python main.py --scenario-name=simple_tag --evaluate-episodes=10
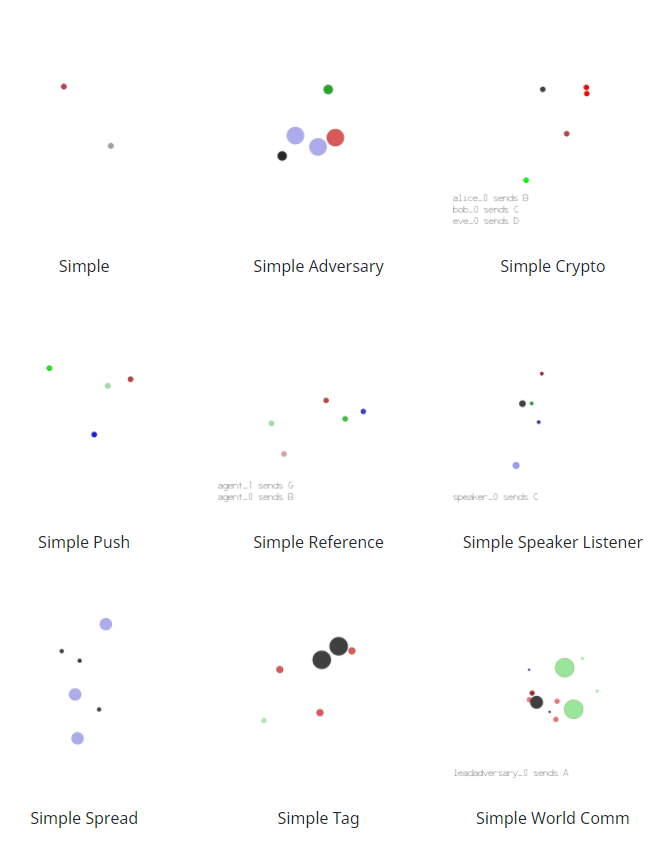
环境列表
| 代码中的环境名称 | 沟通 | 竞争 | 描述 |
|---|---|---|---|
| simple | N | N | 单个代理看到地标位置,根据它与地标的接近程度进行奖励。不是多代理环境——用于调试策略。 |
| simple_adversary.py | (物理欺骗) | N | 是 1 个对手(红色),N 个优秀代理(绿色),N 个地标(通常 N=2)。所有代理都会观察地标和其他代理的位置。一个地标是“目标地标”(绿色)。好的代理根据其中一个与目标地标的接近程度进行奖励,但如果对手靠近目标地标,则获得负面奖励。对手根据它与目标的接近程度获得奖励,但它不知道哪个地标是目标地标。因此,优秀的代理必须学会“拆分”并覆盖所有地标以欺骗对手。 |
| simple_crypto.py (秘密交流) | 是 | 是 | 两个好代理人(爱丽丝和鲍勃),一个对手(夏娃)。Alice 必须通过公共频道向 bob 发送私人消息。Alice 和 bob 会根据 bob 重建消息的程度获得奖励,但如果 eve 能够重建消息,则获得负面奖励。Alice 和 bob 有一个私钥(在每集开始时随机生成),他们必须学会使用它来加密消息。 |
| simple_push.py (远离) | N | 是 | 1 个代理、1 个对手、1 个地标。代理根据与地标的距离进行奖励。如果对手靠近地标,并且代理远离地标,则它会得到奖励。因此,对手学会将代理推离地标。 |
| simple_reference.py | 是 | N | 2 个代理,3 个不同颜色的地标。每个代理都想到达他们的目标地标,只有其他代理知道。奖励是集体的。因此,代理必须学会传达另一个代理的目标,并导航到他们的地标。这与 simple_speaker_listener 场景相同,其中两个代理同时是说话者和听众。 |
| simple_speaker_listener.py (合作交流) | 是 | N | 与 simple_reference 相同,除了一个代理是不动的“说话者”(灰色)(观察其他代理的目标),另一个代理是听者(不能说话,但必须导航到正确的地标)。 |
| simple_spread.py (合作导航) | N | N | N 个代理,N 个地标。根据任何代理与每个地标的距离对代理进行奖励。如果代理与其他代理发生冲突,则会受到惩罚。因此,代理必须学会在避免碰撞的同时覆盖所有地标。 |
| simple_tag.py (捕食者-猎物) | N | 是 | 捕食者-猎物环境。好的代理(绿色)速度更快,并且希望避免被对手(红色)击中。对手速度较慢,并希望打击优秀的代理。障碍物(大黑圈)挡住了去路。 |
| simple_world_comm.py | 是 | 是 | 在论文随附的视频中看到的环境。与 simple_tag 相同,除了 (1) 有食物(蓝色小球),好代理会因为靠近而获得奖励,(2)我们现在有“森林”,可以将代理隐藏在里面,从外面看不到;(3)有一个“领导对手”,可以随时看到代理人,并可以与其他对手沟通,帮助协调追击。 |
通过python main.py --scenario-name=simple_tag --evaluate-episodes=10
修改simple_tag替换环境。
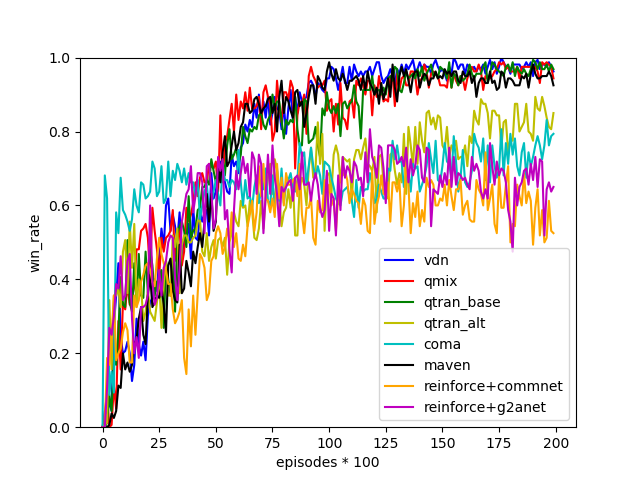
结果
在这项任务中,两个蓝色代理通过最小化它们与绿色地标的最近距离(只有一个需要靠近以获得最佳奖励)来获得奖励,同时最大化红色对手与绿色地标的距离。红色对手通过最小化它与绿色地标的距离来获得奖励;然而,在任何给定的试验中,它不知道哪个地标是绿色的,所以它必须跟随蓝色代理。因此,蓝色代理应该学会通过覆盖两个地标来欺骗红色代理。