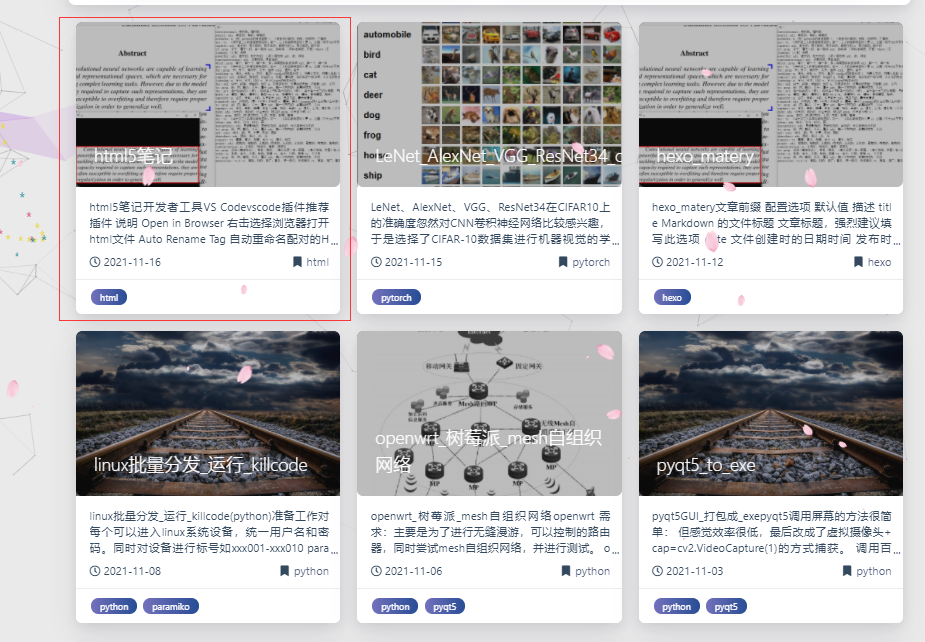
LeNet、AlexNet、VGG、ResNet34在CIFAR10上的准确度
忽然对CNN卷积神经网络比较感兴趣,于是选择了CIFAR-10数据集进行机器视觉的学习。
CIFAR-10

CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片:飞机( airplane )、汽车( automobile )、鸟类( bird )、猫( cat )、鹿( deer )、狗( dog )、蛙类( frog )、马( horse )、船( ship )和卡车( truck )。
每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。
MNIST数据集
MNIST数据集是机器学习领域中非常经典的一个数据集,训练数据集包含 60,000 个样本, 测试数据集包含 10,000 样本. 在 MNIST 数据集中的每张图片由 28 x 28 个像素点构成, 每个像素点用一个灰度值表示.
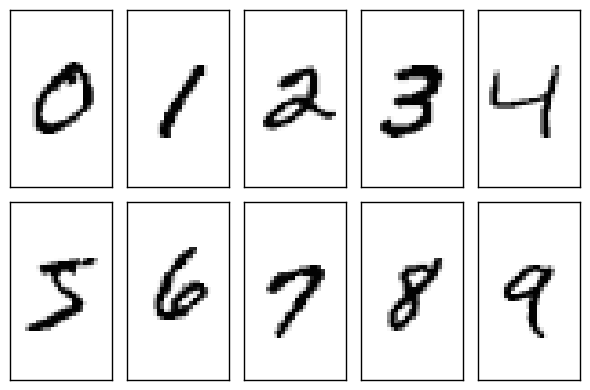
CIFAR-10和与MNIST之间的区别
与MNIST数据集中目比, CIFAR-10 真高以下不同点
(1)、CIFAR-10 是3 通道的彩色RGB 图像,而MNIST 是灰度图像。
(2)、CIFAR-10 的图片尺寸为32 × 32 , 而MNIST 的图片尺寸为28 × 28 ,比MNIST 稍大。
(3)、相比于手写字符, CIFAR-10 含有的是现实世界中真实的物体,不仅噪声很大,而且物体的比例、特征都不尽相同,这为识别带来很大困难。直接的线性模型如Softmax 在CIFAR-10 上表现得很差。
LeNet代码
import torch
import torch.nn as nn
from torch import optim
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
from tqdm import tqdm
transform = transforms.Compose([
transforms.RandomHorizontalFlip(),
transforms.ToTensor()
])
# 定义超参数
BATCH_SIZE = 128 # 批的大小
# CIFAR-10
train_dataset = datasets.CIFAR10('./data1', train=True, transform=transform, download=False)
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0, pin_memory=True)
test_dataset = datasets.CIFAR10('./data1', train=False, transform=transform, download=False)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=0, pin_memory=True)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 定义网络模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
# 卷积层
self.cnn = nn.Sequential(
# 卷积层1,3通道输入,6个卷积核,核大小5*5
# 经过该层图像大小变为32-5+1,28*28
# 经2*2最大池化,图像变为14*14
nn.Conv2d(3, 6, 5),
nn.ReLU(),
nn.MaxPool2d(2),
# 卷积层2,6输入通道,16个卷积核,核大小5*5
# 经过该层图像变为14-5+1,10*10
# 经2*2最大池化,图像变为5*5
nn.Conv2d(6, 16, 5),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 全连接层
self.fc = nn.Sequential(
# 16个feature,每个feature 5*5
nn.Linear(16 * 5 * 5, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.cnn(x)
# x.size()[0]: batch size
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
# 创建模型
net = LeNet().to('cuda')
# 定义优化器和损失函数
criterion = nn.CrossEntropyLoss() # 交叉式损失函数
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 优化器
# 定义轮数
EPOCHS = 50
for epoch in range(EPOCHS):
train_loss = 0.0
for i, (datas, labels) in tqdm(enumerate(train_loader)):
datas, labels = datas.to('cuda'), labels.to('cuda')
# 梯度置零
optimizer.zero_grad()
# 训练
outputs = net(datas)
# 计算损失
loss = criterion(outputs, labels)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# 累计损失
train_loss += loss.item()
print("Epoch : {} , Batch :{} , Loss : {:.3f}".format(epoch+1, i+1, train_loss/len(train_loader.dataset)))
# 保存模型
PATH = 'cifar_net.pth'
torch.save(net.state_dict(), PATH)
# 加载模型
model = net.to('cuda')
model.load_state_dict(torch.load(PATH)) # .load_state_dict() 加载模型
# 测试
correct = 0
total = 0
with torch.no_grad():
for i, (datas, labels) in enumerate(test_loader):
datas, labels = datas.to('cuda'), labels.to('cuda')
# 输出
outputs = model(datas) # outputs.data.shape --> torch.Size([128, 10])
_, predicted = torch.max(outputs.data, dim=1) # 第一个是值的张量,第二个是序号的张量
# 累计数据量
total += labels.size(0) # labels.size() --> torch.Size([128]), labels.size(0) --> 128
# 比较有多少个预测正确
correct += (predicted == labels).sum() # 相同为1,不同为0,利用sum()求总和
print('在10000张测试集图片上的准确率:{:.3f}'.format(correct / total * 100))
# 显示每一类预测的概率
class_correct = list(0. for i in range(10))
total = list(0. for i in range(10))
with torch.no_grad():
for (images, labels) in test_loader:
# 输出
images, labels = images.to('cuda'), labels.to('cuda')
outputs = model(images)
# 获取到每一行最大值的索引
_, predicted = torch.max(outputs.data, dim=1)
c = (predicted == labels).squeeze() # squeeze() 去掉0维[默认], unsqueeze() 增加一维
if labels.shape[0] == 128:
for i in range(BATCH_SIZE):
label = labels[i] # 获取每一个label
class_correct[label] += c[i].item() # 累计True的个数,注意 1+True=2, 1+False=1
total[label] += 1 # 该类总的个数
# 输出正确率
for i in range(10):
print('正确率 : %5s : %2d %%' % (classes[i], 100 * class_correct[i] / total[i]))
AlexNet
class AlexNet(nn.Module):
def __init__(self, num_classes):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=2, padding=1), # 修改了这个地方,不知道为什么就对了
# raw kernel_size=11, stride=4, padding=2. For use img size 224 * 224.
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), )
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 1 * 1, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes), )
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256 * 1 * 1)
x = self.classifier(x)
# return F.log_softmax(inputs, dim=3)
return xVGG
VGG16
# 定义网络模型
class VGG16(nn.Module):
def __init__(self, num_classes=1000):
super(VGG16, self).__init__()
self.features = nn.Sequential(
# 1
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 2
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 3
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 4
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 5
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 6
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 7
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 8
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 9
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 10
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
# 11
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 12
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
# 13
nn.Conv2d(512, 512, kernel_size=3, padding=1),
# nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
# 14
nn.Linear(512, 4096),
nn.ReLU(True),
nn.Dropout(),
# 15
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
# 16
nn.Linear(4096, num_classes),
)
# self.classifier = nn.Linear(512, 10)
def forward(self, x):
out = self.features(x)
out = out.view(out.size(0), -1)
out = self.classifier(out)
return out
VGG19
'''
创建VGG块
参数分别为输入通道数,输出通道数,卷积层个数,是否做最大池化
'''
def make_vgg_block(in_channel, out_channel, convs, pool=True):
net = []
# 不改变图片尺寸卷积
net.append(nn.Conv2d(in_channel, out_channel, kernel_size=3, padding=1))
net.append(nn.BatchNorm2d(out_channel))
net.append(nn.ReLU(inplace=True))
for i in range(convs - 1):
# 不改变图片尺寸卷积
net.append(nn.Conv2d(out_channel, out_channel, kernel_size=3, padding=1))
net.append(nn.BatchNorm2d(out_channel))
net.append(nn.ReLU(inplace=True))
if pool:
# 2*2最大池化,图片变为w/2 * h/2
net.append(nn.MaxPool2d(2))
return nn.Sequential(*net)
# 定义网络模型
class VGG19Net(nn.Module):
def __init__(self):
super(VGG19Net, self).__init__()
net = []
# 输入32*32,输出16*16
net.append(make_vgg_block(3, 64, 2))
# 输出8*8
net.append(make_vgg_block(64, 128, 2))
# 输出4*4
net.append(make_vgg_block(128, 256, 4))
# 输出2*2
net.append(make_vgg_block(256, 512, 4))
# 无池化层,输出保持2*2
net.append(make_vgg_block(512, 512, 4, False))
self.cnn = nn.Sequential(*net)
self.fc = nn.Sequential(
# 512个feature,每个feature 2*2
nn.Linear(512*2*2, 256),
nn.ReLU(),
nn.Linear(256, 256),
nn.ReLU(),
nn.Linear(256, 10)
)
def forward(self, x):
x = self.cnn(x)
# x.size()[0]: batch size
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
ResNet34
ResNet34 model1
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(ResBlock, self).__init__()
# 残差块的第一个卷积
# 通道数变换in->out,每一层(除第一层外)的第一个block
# 图片尺寸变换:stride=2时,w-3+2 / 2 + 1 = w/2,w/2 * w/2
# stride=1时尺寸不变,w-3+2 / 1 + 1 = w
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
# 残差块的第二个卷积
# 通道数、图片尺寸均不变
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
# 残差块的shortcut
# 如果残差块的输入输出通道数不同,则需要变换通道数及图片尺寸,以和residual部分相加
# 输出:通道数*2 图片尺寸/2
if in_channels != out_channels:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2),
nn.BatchNorm2d(out_channels)
)
else:
# 通道数相同,无需做变换,在forward中identity = x
self.downsample = None
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
'''
# 定义网络模型
'''
#定义网络结构
class ResNet34(nn.Module):
def __init__(self, block):
super(ResNet34, self).__init__()
# 初始卷积层核池化层
self.first = nn.Sequential(
# 卷基层1:7*7kernel,2stride,3padding,outmap:32-7+2*3 / 2 + 1,16*16
nn.Conv2d(3, 64, 7, 2, 3),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 最大池化,3*3kernel,1stride(32的原始输入图片较小,不再缩小尺寸),1padding,
# outmap:16-3+2*1 / 1 + 1,16*16
nn.MaxPool2d(3, 1, 1)
)
# 第一层,通道数不变
self.layer1 = self.make_layer(block, 64, 64, 3, 1)
# 第2、3、4层,通道数*2,图片尺寸/2
self.layer2 = self.make_layer(block, 64, 128, 4, 2) # 输出8*8
self.layer3 = self.make_layer(block, 128, 256, 6, 2) # 输出4*4
self.layer4 = self.make_layer(block, 256, 512, 3, 2) # 输出2*2
self.avg_pool = nn.AvgPool2d(2) # 输出512*1
self.fc = nn.Linear(512, 10)
def make_layer(self, block, in_channels, out_channels, block_num, stride):
layers = []
# 每一层的第一个block,通道数可能不同
layers.append(block(in_channels, out_channels, stride))
# 每一层的其他block,通道数不变,图片尺寸不变
for i in range(block_num - 1):
layers.append(block(out_channels, out_channels, 1))
return nn.Sequential(*layers)
def forward(self, x):
x = self.first(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
# x.size()[0]: batch size
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
# 创建模型
net = ResNet34(ResBlock).to('cuda')ResNet34 model2
#定义网络结构
class ResNet34(nn.Module):
def __init__(self, block):
super(ResNet34, self).__init__()
# 初始卷积层核池化层
self.first = nn.Sequential(
# 卷基层1:3*3kernel,1stride,1padding,outmap:32-3+1*2 / 1 + 1,32*32
nn.Conv2d(3, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# 最大池化,3*3kernel,1stride(保持尺寸),1padding,
# outmap:32-3+2*1 / 1 + 1,32*32
nn.MaxPool2d(3, 1, 1)
)
# 第一层,通道数不变
self.layer1 = self.make_layer(block, 64, 64, 3, 1)
# 第2、3、4层,通道数*2,图片尺寸/2
self.layer2 = self.make_layer(block, 64, 128, 4, 2) # 输出16*16
self.layer3 = self.make_layer(block, 128, 256, 6, 2) # 输出8*8
self.layer4 = self.make_layer(block, 256, 512, 3, 2) # 输出4*4
self.avg_pool = nn.AvgPool2d(4) # 输出512*1
self.fc = nn.Linear(512, 10)
def make_layer(self, block, in_channels, out_channels, block_num, stride):
layers = []
# 每一层的第一个block,通道数可能不同
layers.append(block(in_channels, out_channels, stride))
# 每一层的其他block,通道数不变,图片尺寸不变
for i in range(block_num - 1):
layers.append(block(out_channels, out_channels, 1))
return nn.Sequential(*layers)
def forward(self, x):
x = self.first(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avg_pool(x)
# x.size()[0]: batch size
x = x.view(x.size()[0], -1)
x = self.fc(x)
return x
注意事项
- 若第一次运行可以
train_dataset = datasets.CIFAR10('./data1', train=True, transform=transform, download=False)将download改为true. - 其他网络在LeNet基础上替换网络即可运行。
- 参考我之前的文章安装环境Ubuntu系统安装NVIDIARTX30xx显卡驱动,开发环境安装
数据扩充
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_train = transforms.Compose([
# 对原始32*32图像四周各填充4个0像素(40*40),然后随机裁剪成32*32
transforms.RandomCrop(32, padding=4),
# 按0.5的概率水平翻转图片
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])不同网络测试结果
EPOCHS=50
| 网络类型 | LeNet | AlexNet | VGG19 | VGG16 | ResNet34 1 | ResNet34 2 |
|---|---|---|---|---|---|---|
| 准确度 | 58.990% | 64.55% | 84.610% | 83.670% | 78.790% | 85.14% |
| loss | 0.009 | 0.007 | 0.000 | 0.000 | 0.00 | 0.00 |
| plane 准确度 | 66% | 81% | 87% | 88% | 83% | 88% |
| car 准确度 | 70% | 85% | 90% | 90% | 84% | 93% |
| bird 准确度 | 48% | 56% | 74% | 73% | 69% | 79% |
| cat 准确度 | 39% | 32% | 67% | 71% | 59% | 70% |
| deer 准确度 | 58% | 66% | 86% | 86% | 74% | 82% |
| dog 准确度 | 44% | 46% | 77% | 77% | 68% | 75% |
| frog 准确度 | 72% | 65% | 90% | 86% | 84% | 89% |
| horse 准确度 | 65% | 64% | 89% | 83% | 82% | 89% |
| ship 准确度 | 69% | 79% | 91% | 92% | 89% | 92% |
| truck 准确度 | 59% | 64% | 90% | 90% | 86% | 90% |
扩充准确度 EPOCHS=50
| 网络类型 | VGG19 | ResNet34 2 |
|---|---|---|
| 准确度 | 87.220% | 87.09% |
| loss | 0.001 | 0.000 |
| plane 准确度 | 85% | 85% |
| car 准确度 | 93% | 92% |
| bird 准确度 | 80% | 82% |
| cat 准确度 | 76% | 74% |
| deer 准确度 | 86% | 85% |
| dog 准确度 | 82% | 83% |
| frog 准确度 | 90% | 91% |
| horse 准确度 | 88% | 90% |
| ship 准确度 | 93% | 92% |
| truck 准确度 | 94% | 91% |
扩充准确度 EPOCHS=100
VGG19 在10000张测试集图片上的准确率:88.840
正确率 : plane : 91 %
正确率 : car : 96 %
正确率 : bird : 85 %
正确率 : cat : 78 %
正确率 : deer : 88 %
正确率 : dog : 79 %
正确率 : frog : 90 %
正确率 : horse : 93 %
正确率 : ship : 94 %
正确率 : truck : 90 %
| 网络类型 | VGG19 | ResNet34 2 |
|---|---|---|
| 准确度 | 88.84% | 88.05% |
| loss | 0.000 | 0.000 |
| plane 准确度 | 91% | 89% |
| car 准确度 | 96% | 93% |
| bird 准确度 | 85% | 82% |
| cat 准确度 | 78% | 79% |
| deer 准确度 | 88% | 85% |
| dog 准确度 | 79% | 79% |
| frog 准确度 | 90% | 91% |
| horse 准确度 | 93% | 91% |
| ship 准确度 | 94% | 93% |
| truck 准确度 | 90% | 93% |
结论
以上结果可以看出ResNet34 2>VGG19>VGG16>ResNet34 1>AlexNet>LeNet